Evidence data platform
From academic PDFs to decision-ready answers – in seconds, not days
In a 8 week AI product sprint we built an alpha of a trustworthy AI research platform for evidence-based decisions – accurate doc ingestion, fast retrieval, truthful answers, clear provenance, and guardrails by design.
At a glance
Client: Centre for Homelessness Impact (CHI)
Format: AI Product Sprint (8 weeks)
My role: product & tech lead – product strategy, design, prototyping
Team: focused squad of 3 (me, product designer, client lead)
What shipped
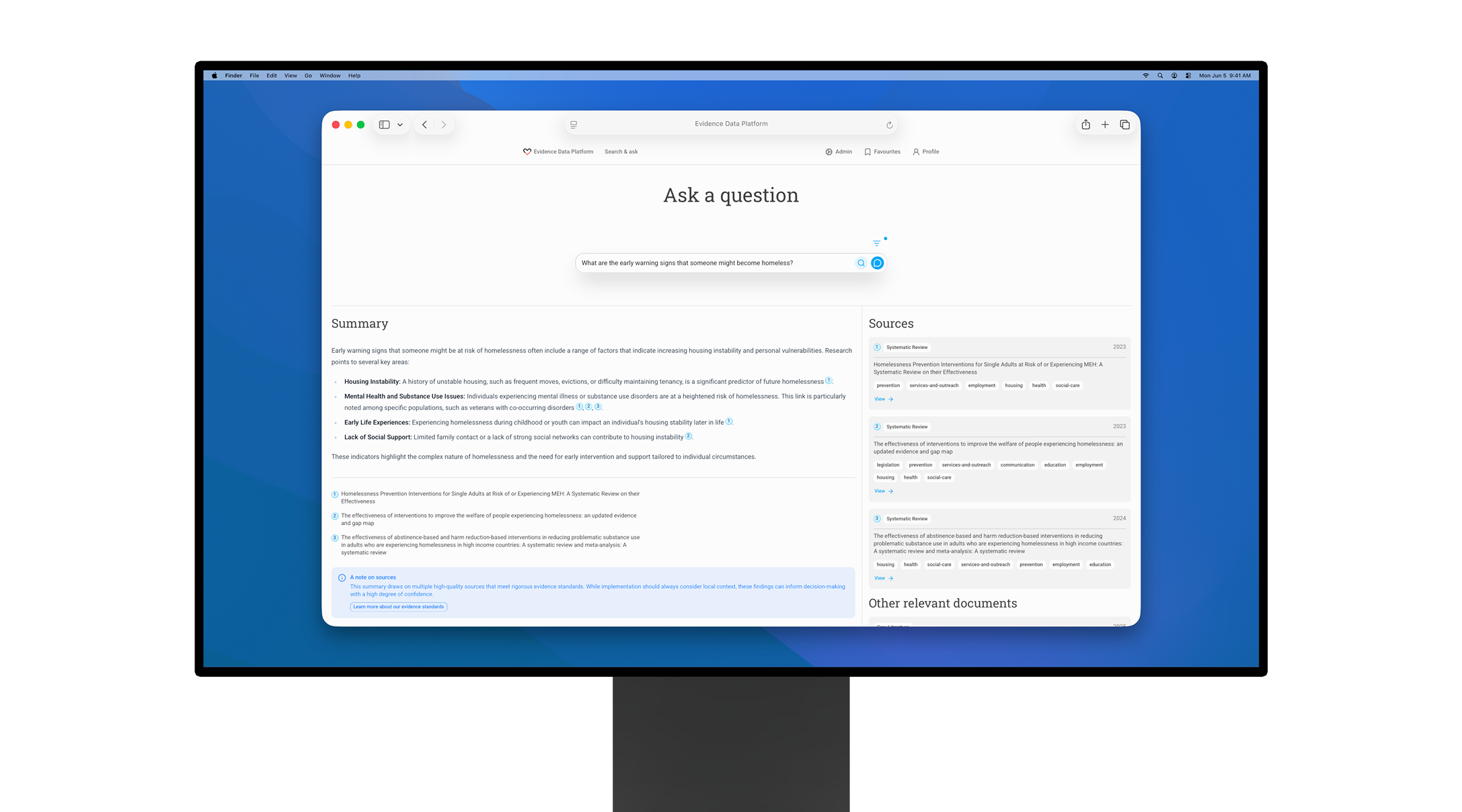
Fully working AI-powered evidence data platform alpha that ingests evidence using AI, extracts attributes, and provides search and Q&A functionality.
The problem
CHI has hundreds of high-quality evidence documents, but finding the right research for a specific user question means hours of digging through academic PDFs sitting on hard drive folders. Teams are duplicating work, missing relevant studies, and risking misinterpretation when they lost track of the original context. The evidence is there – it just isn't accessible when decisions needed to be made.

Key insight – “trust is the interface”
For AI to be useful in evidence-based work, trust must be built into every interaction and algorithm.
At every moment platform needs to provides users with:
understanding where the answer or data came from
how strong/robust the evidence is
the ability to verify and amend things quickly
What we designed and built
A fully functioning alpha of of AI-powered evidence data platform for Centre for Homelessness Impact (CHI):
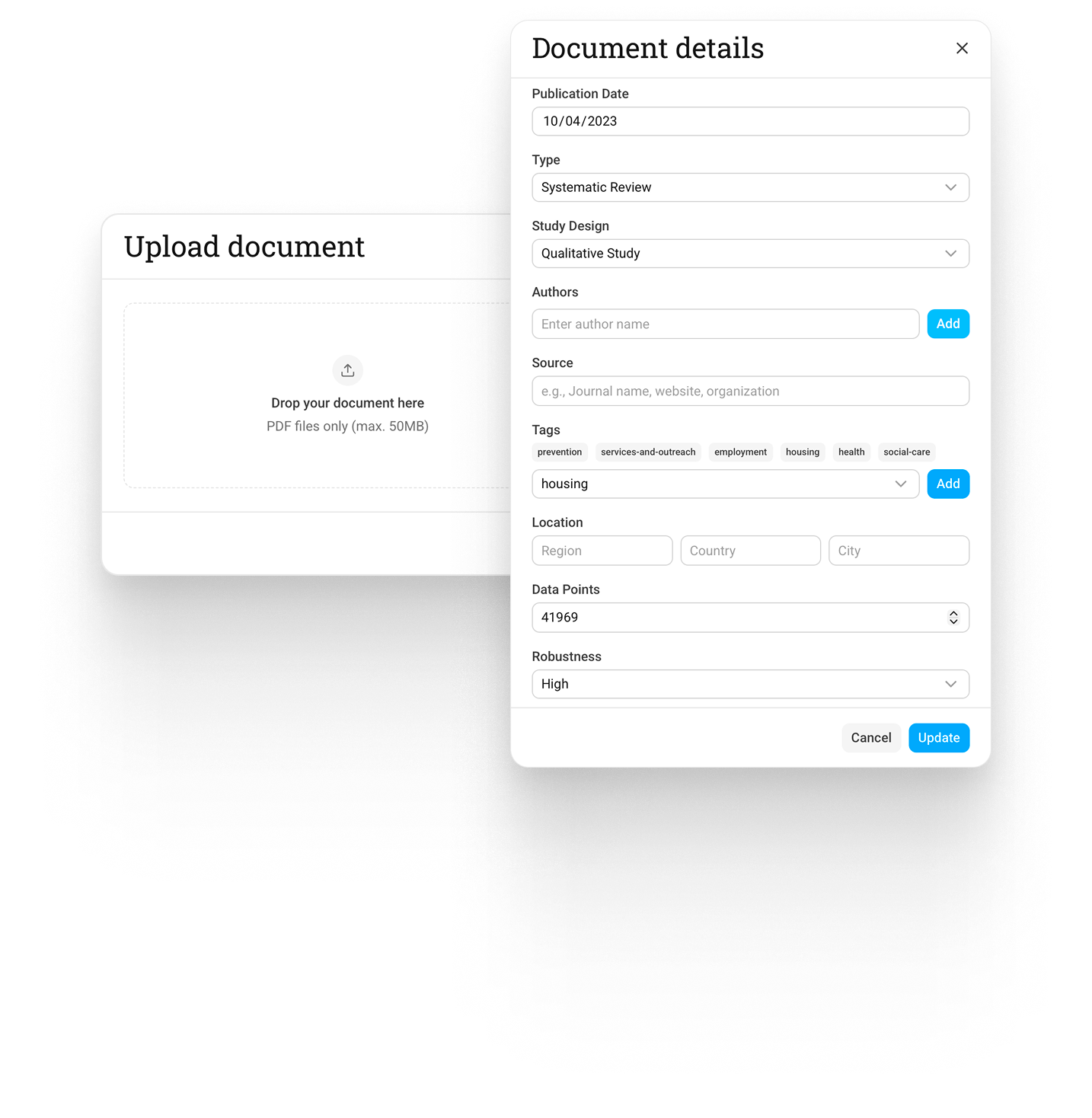
Document ingestion pipeline
From PDFs to metadata and vectors
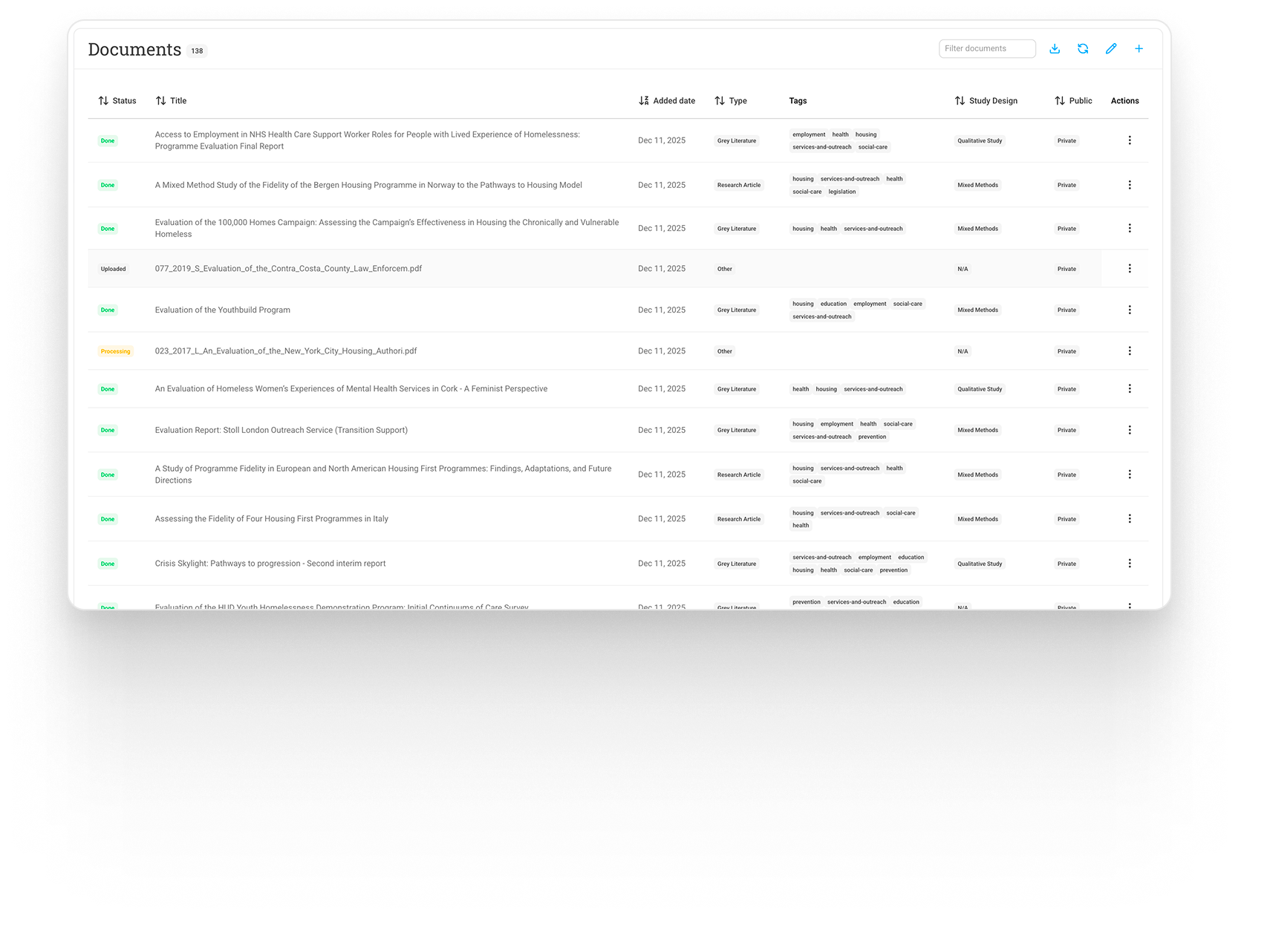
Evidence library
with filtering and permissions

Hybrid search
(keyword + semantic + robustness based) to balance recall and precision
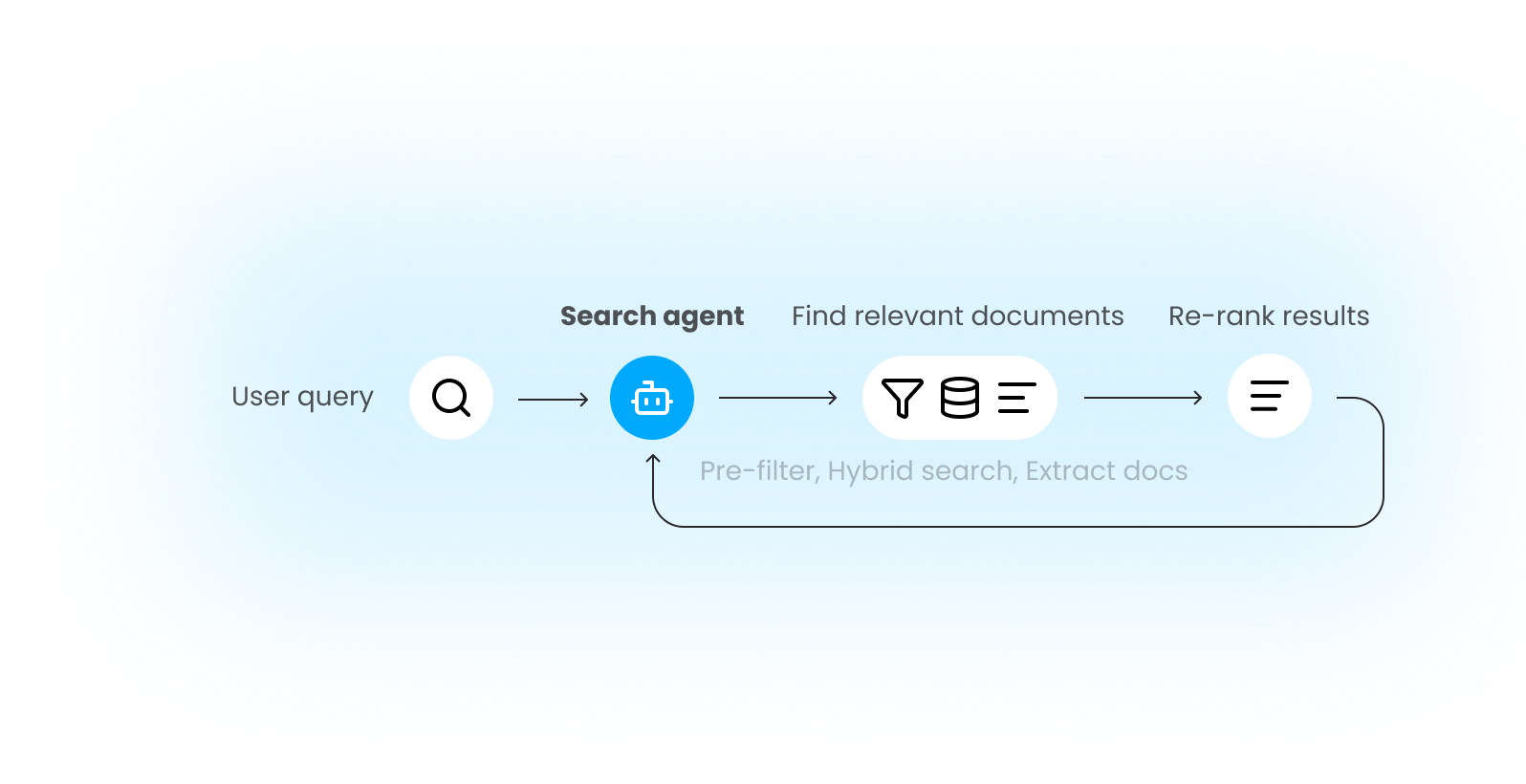
Search agent
with AI-assisted summaries and a citation engine that keeps source grounding prominent
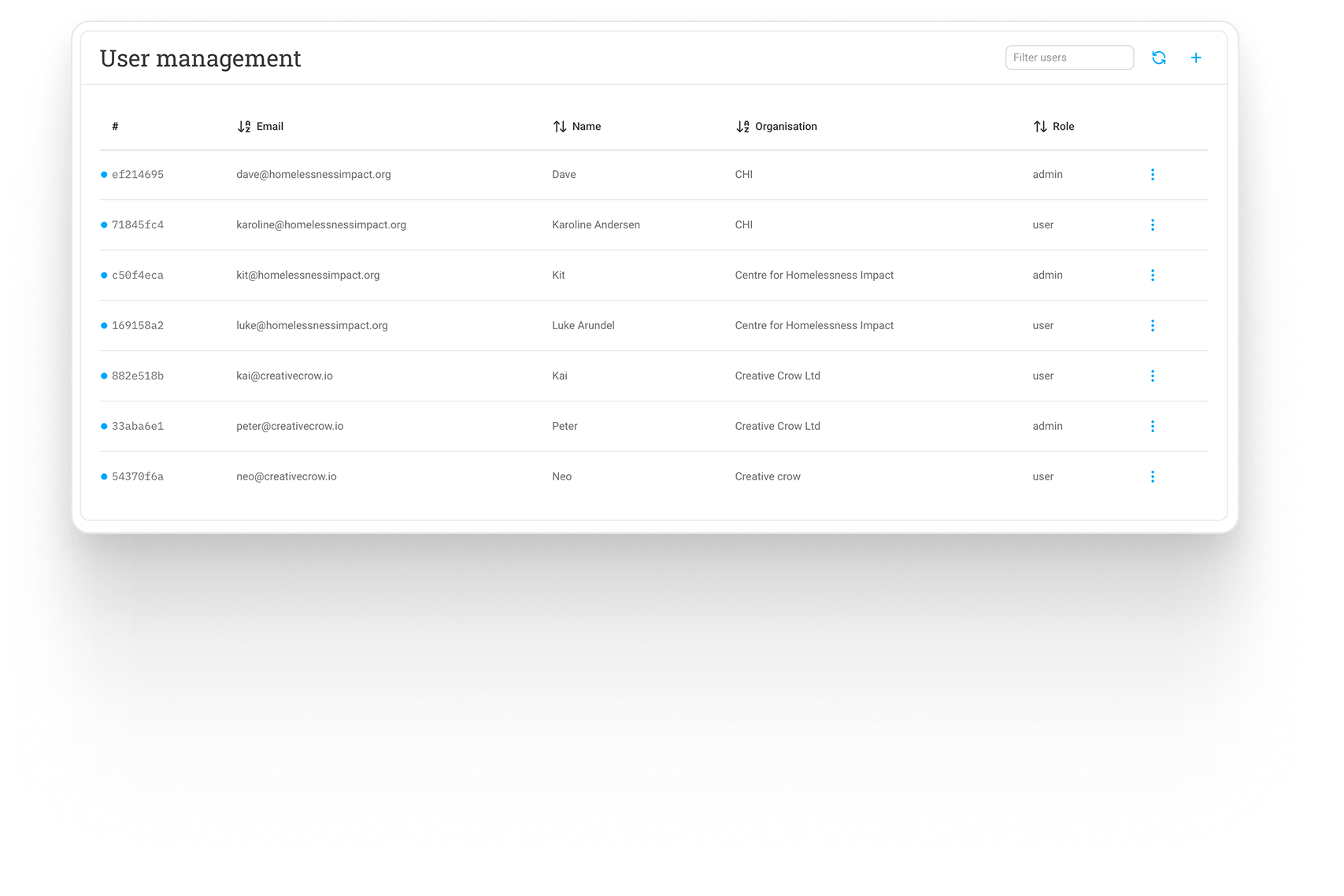
Lightweight user management system
that allows different access levels and editing capabilities
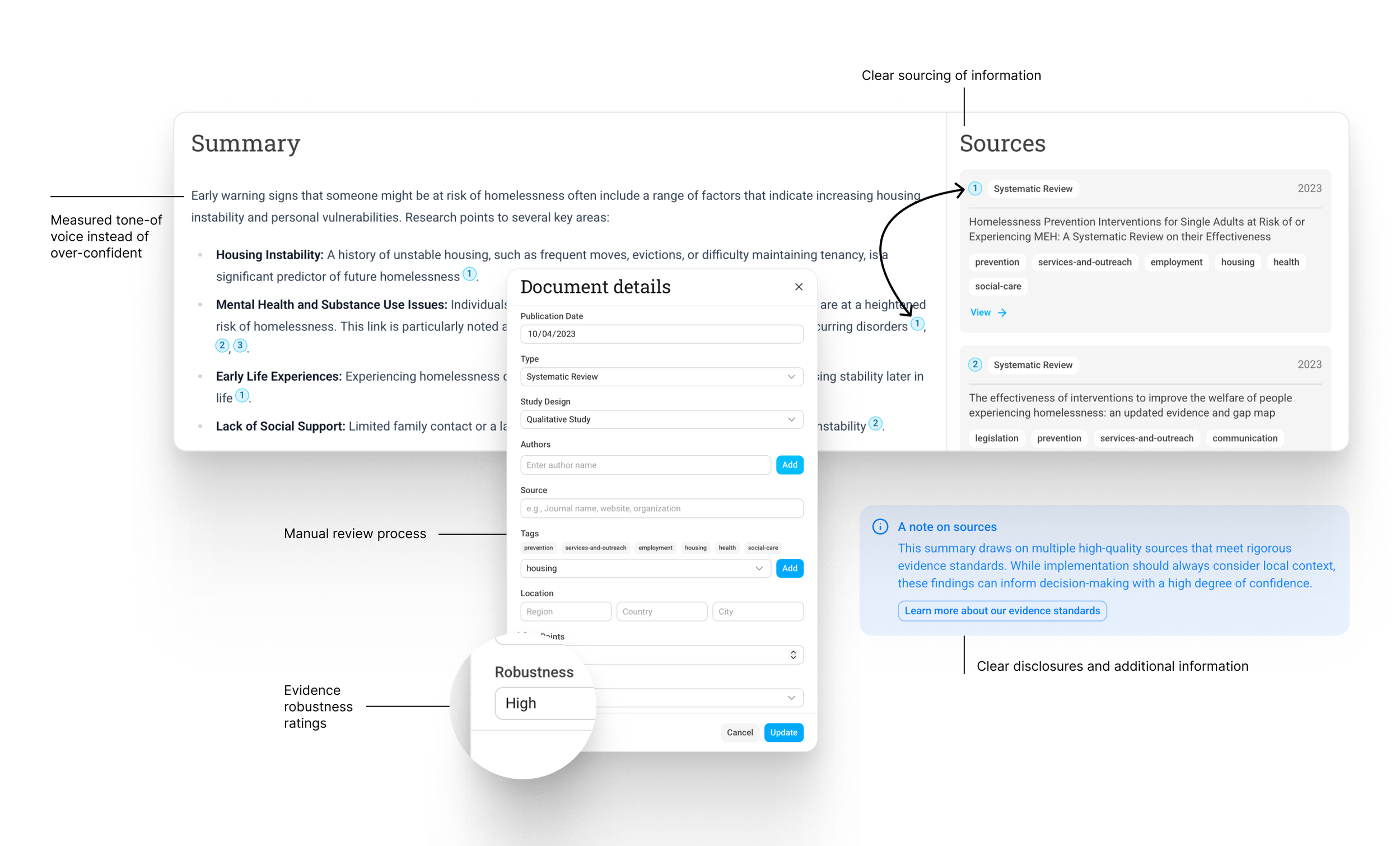
Guardrails, trust and privacy
At each step of the process, we designed the platform to prioritise trust and transparency while minimising personal data use.
The interface always shows document sources and metadata.
During AI ingestion, a human editor reviews and corrects extracted data.
The search agent can only use documents from the CHI library. Our deterministic secondary validation detects any potential fabricated sources or hallucinations.
Each document is assigned a robustness score that prioritises stronger evidence over potentially more relevant but weaker studies during search and answering.
Data collection is minimised for privacy protection. Authentication uses one-time passwords to eliminate password vulnerabilities, analytics operate without cookies or cross-platform tracking, and search queries are anonymised and aggregated into thematic insights using AI.
Sprint timeline

Outcomes
More than 140 documents currently ingested and in testing
8,668,575 characters of text indexed
5 different AI models used (each for specific task)
Extremely high accuracy in document content and attribute extraction
High-quality AI-generated answers with strong contextual relevance
2.1s avg. hybrid search latency (semantic + syntactic + weighted robustness)
9-11s full answer generation time
Solid foundation for further development towards Beta and beyond
What I learned
Guardrails are UX, not policy documents. Trust and validation needs to be built into the platform from the start, not as a cookie banner. This way we can make the experience frictionless and actually help users instead of burdening them.
Hallucinations are not a thing of the past… yet. Even with the best models, hallucinations still happen. Designing for detectability, verifiability and easy correction is key to building trust.
Hybrid search beats purity. Semantic search on its own is rarely enough. Having the ability to tweak the influence of different search types (semantic, syntactic, robustness) allows for much better control over results and tradeoffs between recall and precision.
If your org has valuable documents but can’t reliably find answers in them I'd love to chat about what we learned and which approaches might apply to your context.